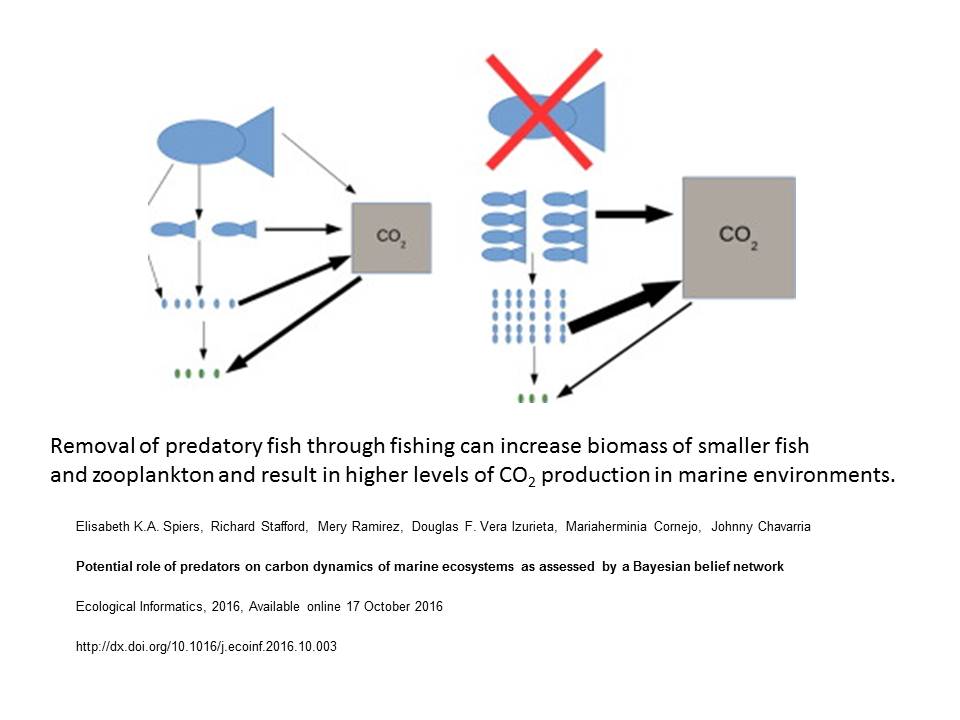
The recent report from the British Ecological Society has reviewed a wide range of Nature-based solutions for climate change mitigation. It does clearly state, in multiple locations, that while there are many benefits of NbS, they are not a substitute for heavy emissions cuts. Lots of different habitats and landscapes can capture CO2, but just how much?
This article is a very rough set of calculations based on the figures in the marine chapter of the report. It shouldn’t be treated as fully scientifically sound (unlike the figures from the report itself), nor used to measure any kind of net zero target.
Disclaimer aside (but please bear it in mind) – how good are the oceans at offsetting emissions?
The answer – currently, even restoring seagrass and saltmarsh habitats, less than 100th of the UK emissions. However, before getting too despondent, NbS are NOT a substitute for emission reduction. If we can move to a per-capita footprint, roughly the size of Kenya, then we get to about 15% of emissions absorbed.
Of course, the UK is small, even in terms of its EEZ (outside of overseas territory) and densely populated. Scaling up the figures (with lower certainty) to the entire world, and assuming we can all reduce per-capita footprints to that of an average Kenyan, just over 50% of emissions can be sequestered by the ocean. This may be an underestimate too – with healthier oceans, come better fish stocks, greater productivity, and algae and phytoplankton increases will all boost these figures.
So, marine NbS can play a huge role in addressing climate change, and address biodiversity issues too. However, this only applies if we can make big emissions cuts in the very near future.
Calculations
Quick calculations – carbon sequestration in the UK and globally
This post is designed to create a few simple ‘back of an envelope’ calculations to estimate the benefits of marine NbS in the UK. The figures are taken from the marine and coastal chapter of the British Ecological Society’s Nature-based Solutions report.
92% of seagrass has potentially been lost. Currently around 8,400 ha of seagrass exists in the UK.
8400/0.08 (the 8% remaining) = 105000 ha of seagrass
New seagrass captures around sequesters CO2 at the rate of 1.3 tonnes per hectare per year, moving to around 5 tonnes for fully established seagrass beds
= 136000 tonnes per year if newly restored
> 500,000 tonnes once better established
Saltmarsh through shoreline management plans in the UK
Around 3000 ha new saltmarsh by 2030
Restored saltmarsh sequesters CO2 at 3.8 tonnes CO2 per hectare per year
So, 11,400 tonnes CO2 per year from new saltmarsh
- 46,000 ha of existing saltmarsh sequestering at around 5 tonnes per year
=11,400 + (46,000*5) = 241,400 tonnes CO2 per year
Coastal shelf sediments 388,000 tonnes per year. Coastal shelf is 9% of UK waters. However, most benthic habitats are sand/mud.
So – (388,000 / 0.09) / 2 (as ‘safety factor’ other sediments may be worse) = 2,155,556 tonnes per year.
Boosting phytoplankton and seaweed growth could boost this even further.
So, UK seas, excluding overseas territory ~ 2,750,000 tonnes CO2 per year.
Currently UK produces over 350 million tonnes CO2 per year, or 5.8 tonnes per person. However, Kenya’s per capita emissions are around 0.3 tonnes per person, meaning UK could produce 18.2 million tonnes (or less) with big emissions cuts.
UK is highly populated and relatively small. UK waters are 773,676 km2 (excluding overseas territories)
Globally the seas cover 361 million km2 or 466 times more. As a very rough calculation as lots changes with location, and the UK also has more coastal habitat than ‘average’ ocean, the sea may be able to sequest in the range of 1,281,500,000 tonnes of CO2 per year. With a population of 8 billion people, and emissions per capita equivalent to Kenya at present, that’s a total emissions scenario of 2.4 billion tonnes CO2 per year. Roughly half of this, with considerable potential for higher figures, could be sequestered by the oceans, if they are restored and protected to optimal condition.